![]() Comme annoncé au Meetup SNDS #5, nous publions une version synthétique (=factice) des données du SNDS.
Comme annoncé au Meetup SNDS #5, nous publions une version synthétique (=factice) des données du SNDS.
Voici par exemple un aperçu de la table ER_PHA_R du DCIR.
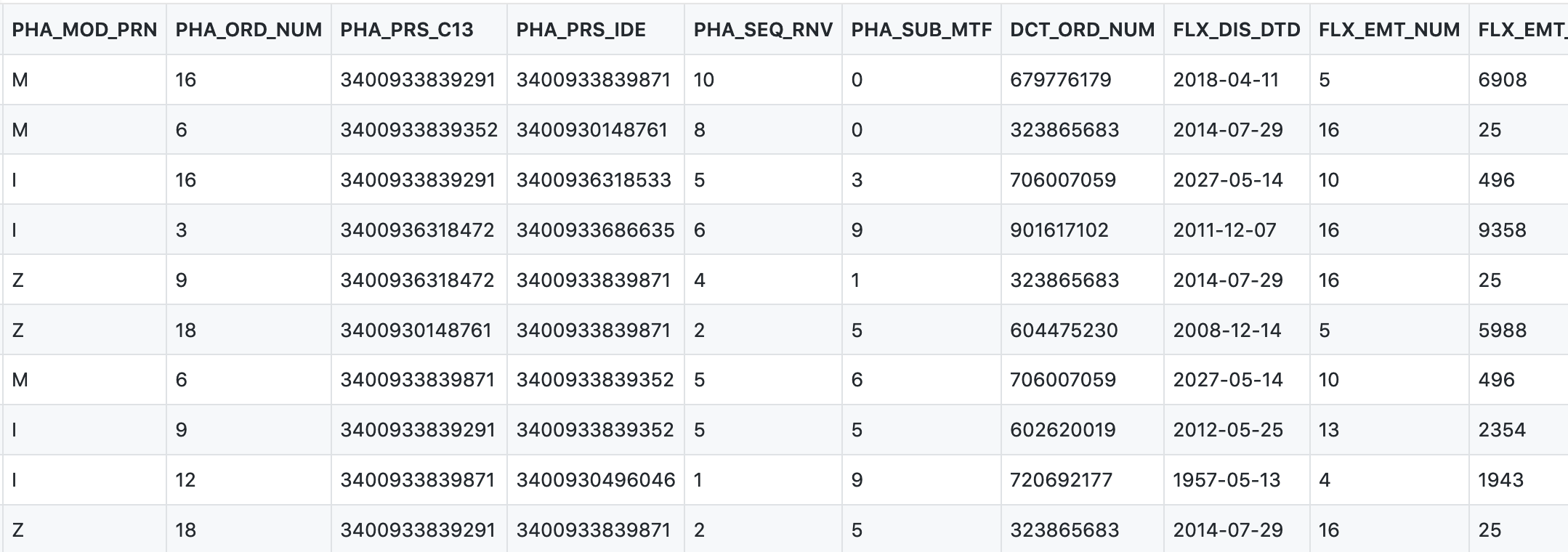
![]() Ces données ont pour objectif de faciliter la prise en main du SNDS, la création d’exercices, ou le test de programmes.
Ces données ont pour objectif de faciliter la prise en main du SNDS, la création d’exercices, ou le test de programmes.
Elles sont générées à partir du schéma formel du SNDS, qui alimente par ailleurs le dictionnaire interactif et la section tables de la documentation.
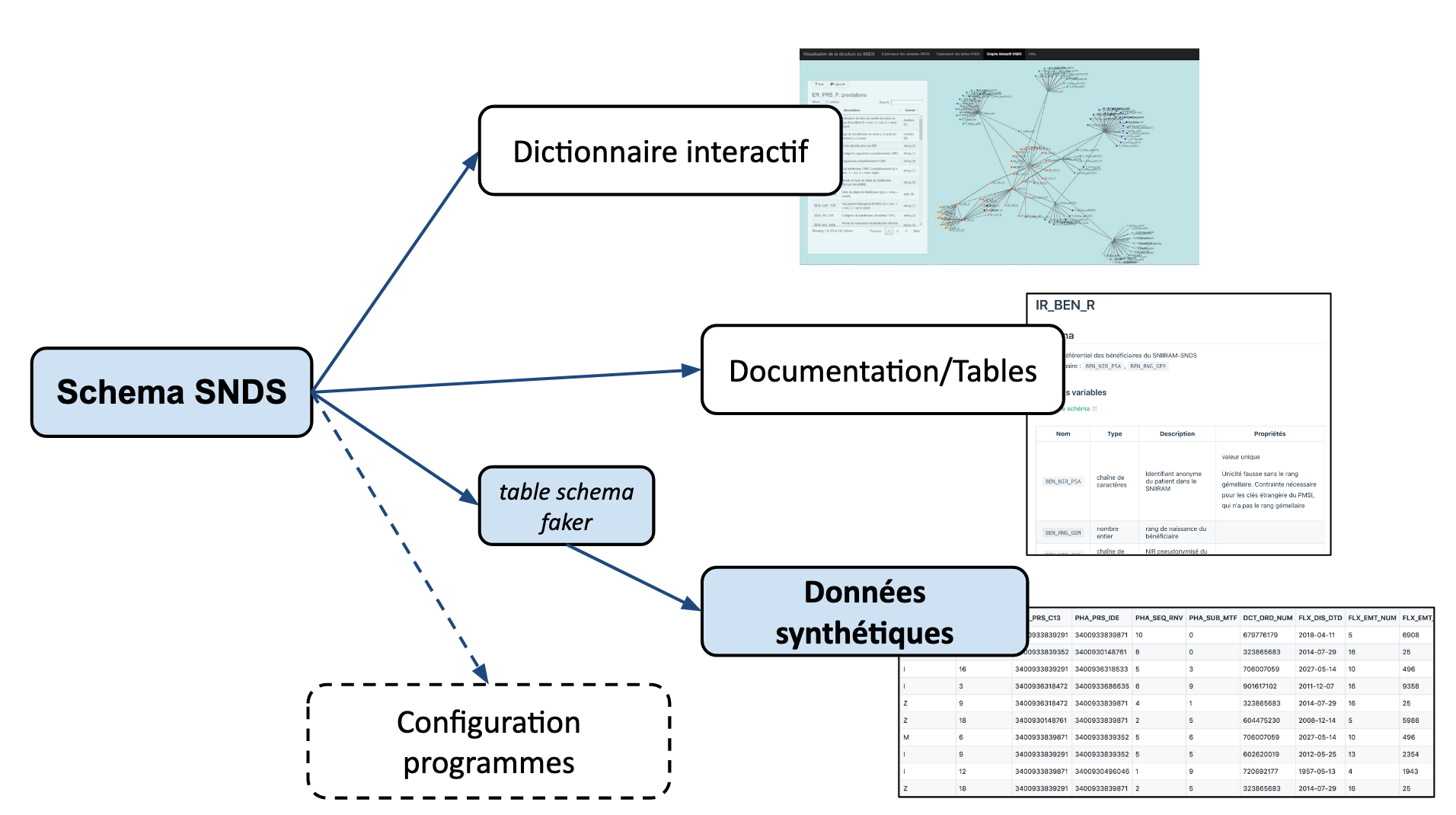
Une page dédiée de la documentation présente cette nouvelle ressource à destination de la communauté. https://documentation-snds.health-data-hub.fr/ressources/donnees_synthetiques.html
![]() Ce produit a vocation à s’enrichir et se compléter, à partir des besoins exprimés.
Ce produit a vocation à s’enrichir et se compléter, à partir des besoins exprimés.
N’hésitez pas à poser vos questions ci-dessous !
![]()
![]()
Ce résultat est le fruit d’une collaboration entre de multiples personnes, créditées ci-dessous.
Crédits : schéma formel
- Le schéma formel du SNDS a été mis en place début 2019 à la DREES par Pierre-Alain Jachiet et Viktor Jarry, à partir du dictionnaire interactif compilé par Mathieu Doutreligne et Claire-Lise Dubost.
- Ce schéma a été complété et corrigé à partir des dictionnaires de la Cnam : le Kwikly et les fichiers sources du dictionnaire du portail
- Ce schéma a été spécifiquement corrigé et complété pour les données synthétiques, via l’ajout de contraintes et de nomenclatures, par Anne Cuerq, Emmanuel Stranadica, Salma El Oualydy et Maeva Kos du Health data hub
- D’autres contributions ponctuelles au schéma du SNDS sont visibles dans l’historique des commits.
- Vous pouvez également contribuer à la documentation des tables et de leurs schémas.
Crédits : librairie tsfaker
- La librairie tsfaker, pour
table schema faker, a été développée par Pierre-Alain Jachiet (DREES). Elle s’appuie sur le standard Table Schema, avec une attention particulière sur la gestion des clés étrangères. - Cette librairie est distribuée sur PyPI, et peut-être utilisée sur d’autres schémas. Des évolutions sont envisagées pour produire des données plus réalistes, sans pour autant chercher à respecter des contraintes statistiques multi-colonnes complexes.
- Des améliorations et corrections ont été apportées par Maeva Kos et Salma El Oualydy (Health data hub) pour gérer les booléens, et le format des dates.